问题
- kubernates 是什么, kubernates 解决了什么问题?
- kubernates 该如何使用?
- 集群中资源是如何调度的?
k8s 是什么, 解决了什么问题
kubernates 是 Google 公司开源的一个容器编排与调度管理框架, 当前由 CNCF 托管.
解决了分布式系统情况下, 容器的编排与调度问题.
发展历史
-
2003-2004 年, Google 发布 Borg 系统, 3-4 人开发.
主要用于管理长时间运行的生产服务和批处理服务. Brog 将上述两种服务所需要的的机器统一成一个池子, 以便提高资源利用率, 同时降低成本.
之所以能够实现跨机器的资源共享以及进程隔离, 是因为可以拿到 Linux 内核的容器支持.
-
… 年, 越来越多的应用被开发并运行在 Borg上, Google 团队开发了一个工具系统.
工具系统提供配合和更新 job 的机制, 可以预测资源需求, 动态的推送配置文件, 服务发现, 负载均衡, 自动扩容, 机器的生命周期管理, 额度管理等等.
由于要适配不同团队的需求, Borg 发展成了 ad-hoc 系统(即席查询, 用户根据自己的需求,灵活的选择查询条件,系统能够根据用户的选择生成相应的统计报表)集合, Borg 使用者可以使用不同的配置语言和进程来配置与沟通.
-
2006-2007 年, Paul Menage和Rohit Seth 提出了 cgroups, 并且被合并到2.6.24版的内核中
-
2013 年左右, 处于提升 Borg 生态系统软件工程的愿景, Google 发布了 Omega 集群管理系统.
Omega 把很多 Borg 内已经被认证的成功的模式搬过来, 同时从头开始搭建一个更加一致性的构架. 添加了控制面板, 调度器等等, 以此来优化偶尔发生的资源冲突问题. 同年, docker 正式出道.
-
2014 年左右, Google 发布了 kubernates. 同年, Microsoft, Red Hat, IBM, Docker 等加入 kubernates 社区
-
2015 年, 成立了 CNCF 基金会, 托管 kubernates
-
2016 年左右, kubernates 成为主流.
在 CloudNative 2016 大会上, 来自全世界的贡献值和开发者一起交流kubernates, Fluentd, Promethues等云原生技术(采用开源堆栈 K8S+Docker 进行容器化,基于微服务架构提高灵活性和可维护性,借助敏捷方法、DevOps支持持续迭代和运维自动化,利用云平台设施实现弹性伸缩、动态调度、优化资源利用率)
-
2017 年左右, 各大互联网厂商开始纷纷支持 kubernates. 同年, istio 正式出道. Docker 容器大战正式结束, 成功上位, 作为 kubernates 容器运行时的标配.
-
2018 年左右, 无人不知 kubernates. 国内不论大小厂商开始进行云原生落地.
Borg/Omega/K8S关联
详情见: https://queue.acm.org/detail.cfm?id=2898444
k8s特点
- 可移植性: 支持公有云, 私有云, 混合云, 多重云
- 可扩展性: 模块化, 插件化, 可挂载, 可组合
- 自动化: 自动部署, 自动重启, 自动复制, 自动伸缩/扩展
k8s 该如何使用
环境准备篇
本地开发环境
详情见: https://github.com/chaimch/k8s-for-docker-desktop
云羊毛环境
GCP 羊毛, 详情见: https://console.cloud.google.com/freetrial
katacoda羊毛, 详情见: https://katacoda.com/learn
入门
自动补全提示
- 安装 bash-completion
yum install bash-completion - 设置 kubectl 的别称
alias k=kubectl - bash 环境下, 调整别称 k 的自动补全
source <(kubectl completion bash | sed s/kubectl/k/g) - zsh 环境下, 调整 k 的自动补全
source <(kubectl completion zsh) - 设置切换名称空间别称
alias kcd='k config set-context $(k config current-context) --namespace'
hello world
创建配置
apiVersion: apps/v1
kind: Deployment
metadata:
name: nginx-deployment
spec:
selector:
matchLabels:
app: nginx
replicas: 2
template:
metadata:
labels:
app: nginx
spec:
containers:
- name: nginx
image: nginx:1.7.9
ports:
- containerPort: 80
创建应用
kubectl create -f 我的配置文件
查看应用
$ kubectl get pods -l app=nginx
NAME READY STATUS RESTARTS AGE
nginx-deployment-67594d6bf6-9gdvr 1/1 Running 0 10m
nginx-deployment-67594d6bf6-v6j7w 1/1 Running 0 10m
Kubernates 官方
详情见: https://kubernetes.io/docs/tutorials/kubernetes-basics/
为什么需要 Pod
容器的本质是进程, Kubernates 的本质是操作系统
pstree -g
systemd(1)-+-accounts-daemon(1984)-+-{gdbus}(1984)
| `-{gmain}(1984)
|-acpid(2044)
...
|-lxcfs(1936)-+-{lxcfs}(1936)
| `-{lxcfs}(1936)
|-mdadm(2135)
|-ntpd(2358)
|-polkitd(2128)-+-{gdbus}(2128)
| `-{gmain}(2128)
|-rsyslogd(1632)-+-{in:imklog}(1632)
| |-{in:imuxsock) S 1(1632)
| `-{rs:main Q:Reg}(1632)
|-snapd(1942)-+-{snapd}(1942)
| |-{snapd}(1942)
| |-{snapd}(1942)
| |-{snapd}(1942)
| |-{snapd}(1942)
在真正的操作系统中, 进程往往是以进程组的方式被组织在一起. 比如 rsyslogd 程序, 负责 linux 日志处理. 其中主程序 main, 和内核日志模块 imklog 等同属于 1632 进程组. 这些进程之间相互协作.
如果将 rsyslogd 应用容器化, 由于受限于容器的“单进程模型”(容器没有管理多个进程的能力),这三个模块往往需要被分别制作成三个不同的容器. 一旦 main 容器所在的节点不足以承担三个容器同时运行时候, 就容易出现成组调度问题.
但是在 Kubernates 中就存在这种问题, Pod 是 Kubernetes 里的原子调度单位, 统一按照 Pod 而非容器的资源需求进行计算调度. 一般容器间会发生直接的文件交换, 使用 localhost 或 socket 文件进行本地通信, 非常频繁的远程调用, 共享 ns 等适合需要将多个容器放到同一个 pod 中.
pod 实现原理
Pod 里的所有容器, 共享的是同一个 Network Namespace, 并且可以声明共享同一个 Volume.
Kubernates 真正处理的还是 linux 容器的 ns 和 cgroups, 不并存在 pod 的边界或者隔离环境. pod 里所有的容器, 共享同一个 network namespace, 并且可以声明共享同一 volume. 相当于 A 和 B 两个容器的 pod, 等同于容器 A 共享容器 B 的网络和 volume.
通过以下命令就可以实现
docker run --net=B --volumes-from=B --name=A image-A
但是, 上述的方式存在一个问题. B 容器必须要在 A 容器之前启动, 依次类推多个容器之前就需要去维护拓扑关系. 因此在 Kubernates 中会直接首先创建一个 infra 的容器, 这样其他的容器就可以直接以 Join Network Namespace 方式加入进来, 其他的容器直接就只是对等关系, 彼此不会相互依赖.
容器设计模式
详情见: https://www.usenix.org/conference/hotcloud16/workshop-program/presentation/burns
核心思想: Pod 对应传统环境的机器, 容器对应机器中的用户程序. 故凡是调度, 网络, 存储, 以及安全相关的属性, 基本都是 Pod 级别.
pod 进阶玩法
传统的 pod 声明如下, 字段过多, 业务与运维不分家
apiVersion: v1
kind: Pod
metadata:
name: website
labels:
app: website
role: frontend
annotations:
podpreset.admission.kubernetes.io/podpreset-allow-database: "resource version"
spec:
containers:
- name: website
image: nginx
volumeMounts:
- mountPath: /cache
name: cache-volume
ports:
- containerPort: 80
env:
- name: DB_PORT
value: "6379"
volumes:
- name: cache-volume
emptyDir: {}
开发人员提交的 pod 声明如下
apiVersion: v1
kind: Pod
metadata:
name: website
labels:
app: website
role: frontend
spec:
containers:
- name: website
image: nginx
ports:
- containerPort: 80
运维人员定义 PodPreset 对象, 由运维管控线上环境的 labels, env, volumes, volumeMount 等
apiVersion: settings.k8s.io/v1alpha1
kind: PodPreset
metadata:
name: allow-database
spec:
selector:
matchLabels:
role: frontend
env:
- name: DB_PORT
value: "6379"
volumeMounts:
- mountPath: /cache
name: cache-volume
volumes:
- name: cache-volume
emptyDir: {}
创建 pod
$ kubectl create -f preset.yaml
$ kubectl create -f pod.yaml
架构图
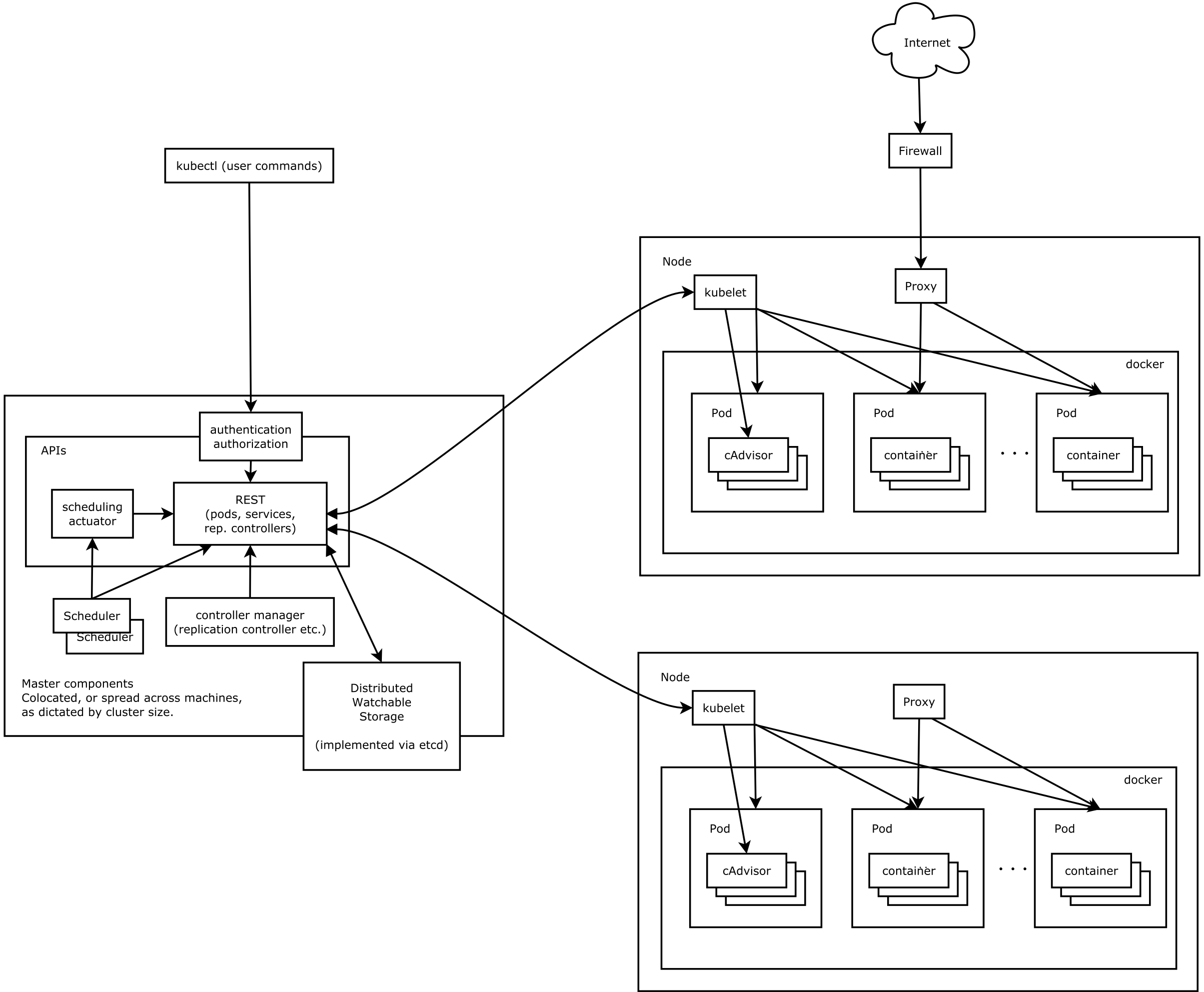
组件功能
kubectl
官方提供的 CLI, 可以以交互式对 Kubernates API Server 进行操作. kubectl 发送相应的 http 请求, 由 Kubernates API Server 处理后返回并展示出结果.
kube-apiserver
负责将 Kubernates 的资源组/资源版本/资源以 restful 风格的形式对外暴露并提供服务. Kubernates 集群中的所有组件都通过 kube-apiserver 组件操作资源对象.
特点
- 所有资源对象都封装成 restful 风格的 api 接口进行管理
- 集群状态管理和数据管理, 是唯一与 etcd 集群交互的组件
- 拥有丰富的集群安全访问机制, 以及认证, 授权及准入控制器
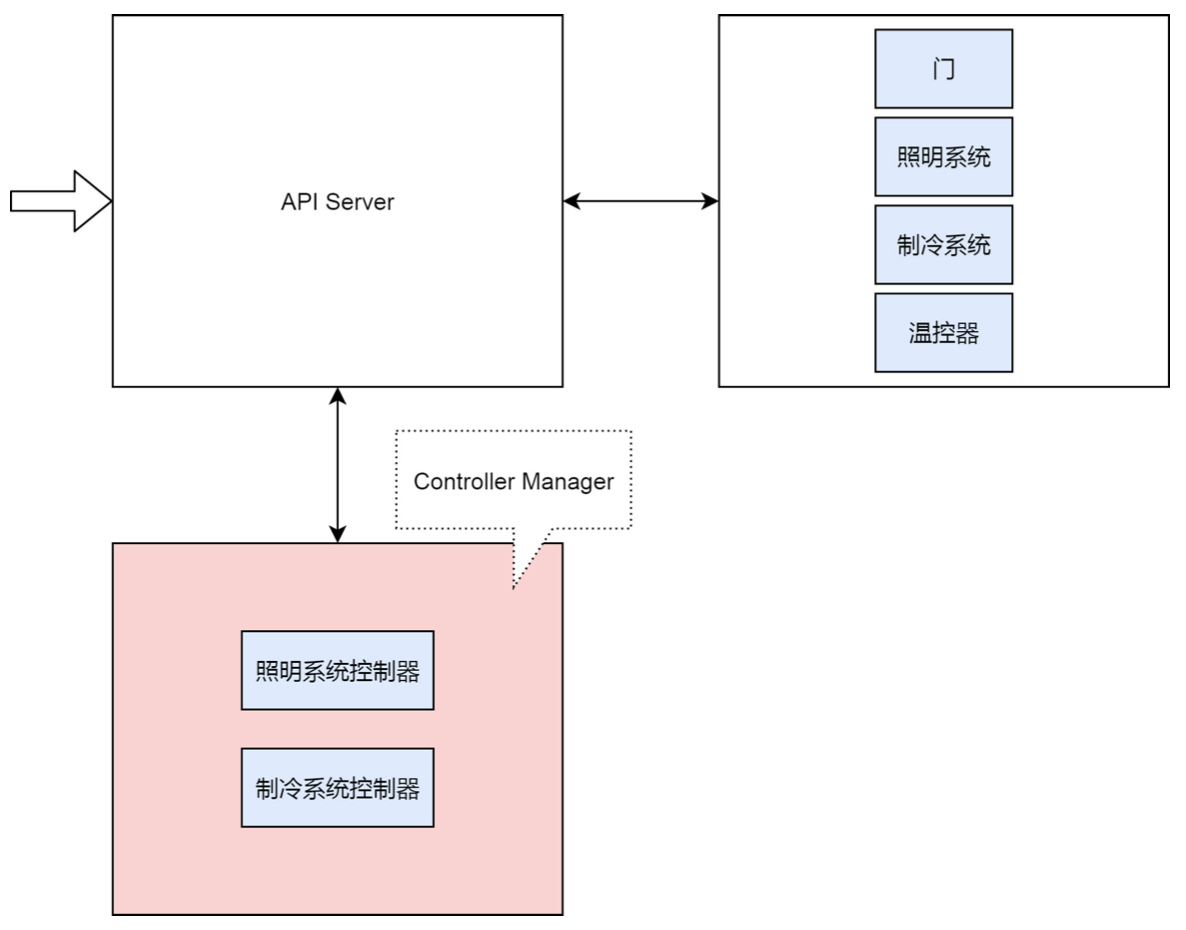
kube-controller-manager
管理 Kubernates 集群中Node节点, Pod副本, 服务, Endpoint端点, Namespace 命名空间, Service Account 服务账户, ResourceQuota 等. eg: 某个节点宕机时候, Controller Manager 会及时发现并执行自动化修复流程.
Controller Manager 具备高可用性, 基于 etcd 集群上的分布式锁实现领导者选举机制. 多个实例同时运行, 通过 kube-apiserver 提供的资源锁进行选举竞争.
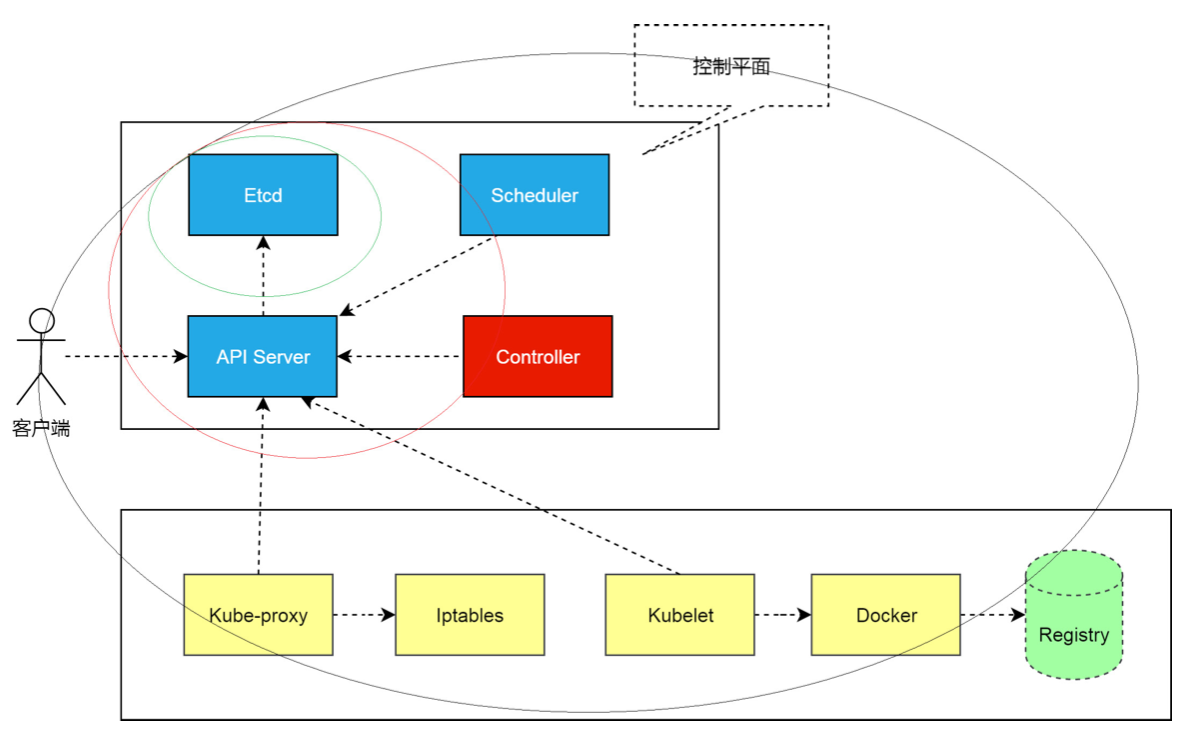
| 简化版本的 Kubernates 架构图 | 简易版本冰箱架构 |
|---|---|
 |
 |
类似冰箱一样, 对 Kubernates 的操作都需要统一的入口管理, 即通过 api-server .
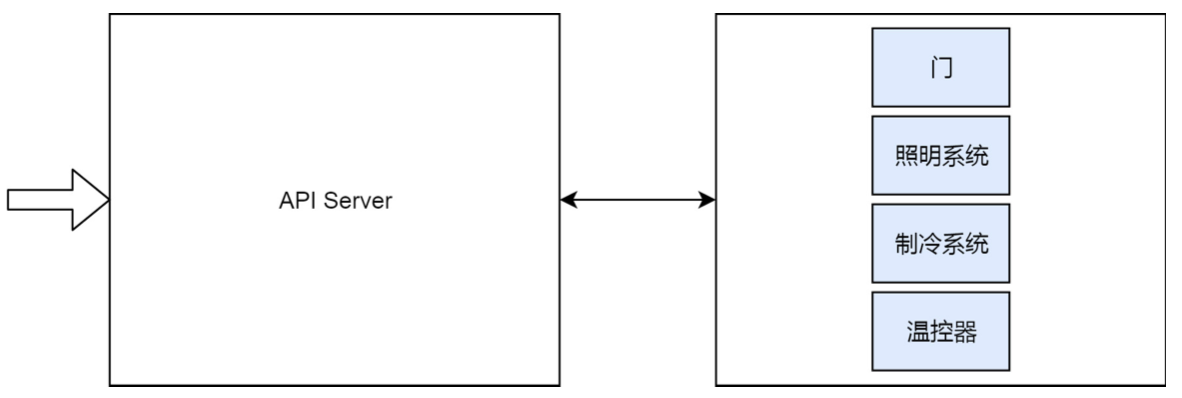
| 冰箱 V1.0 | 冰箱 V2.0 |
|---|---|
 |
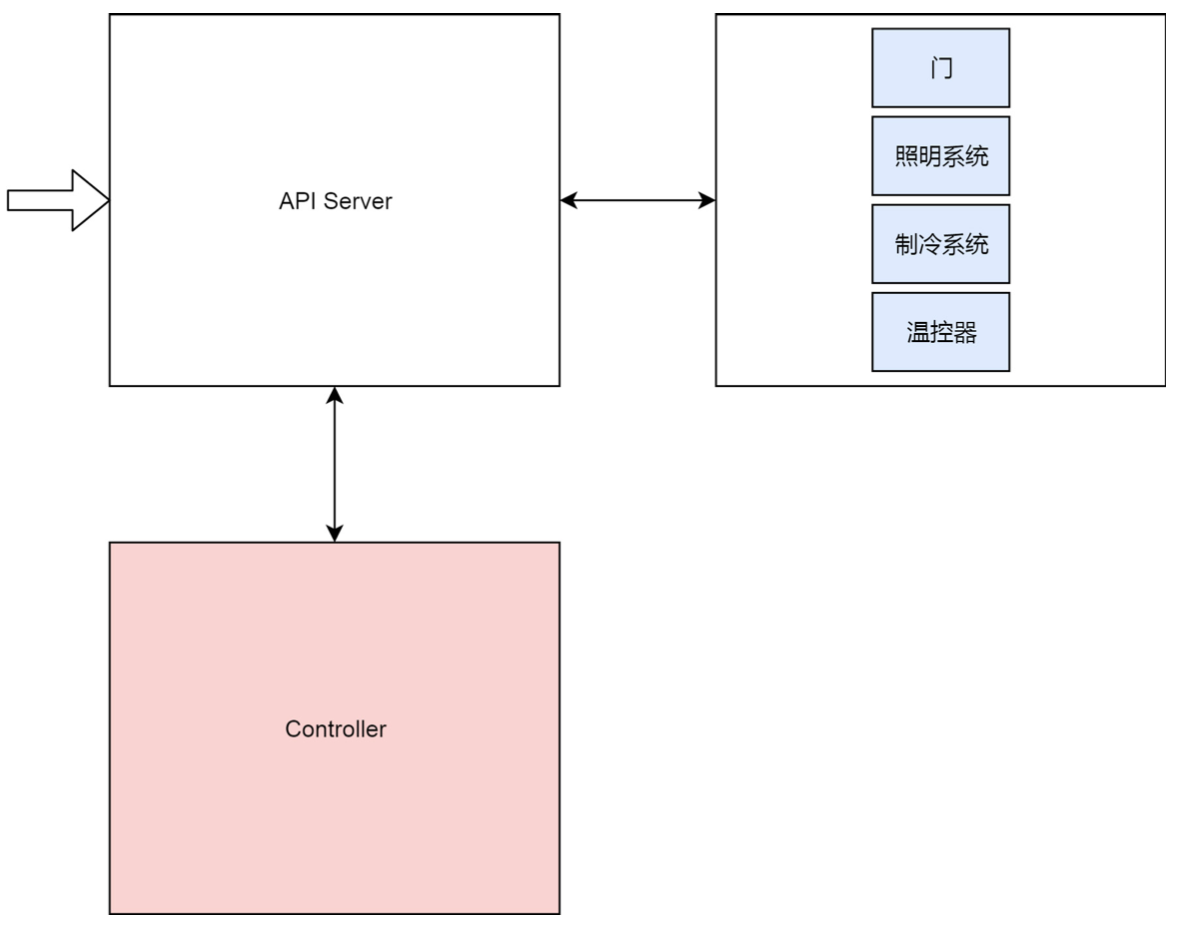 |
控制器专门用于控制各个系统的状态. 打开门时候, 控制器监控到门的变化, 替用户打开灯. 用户按下温控器时候, 控制器观察到用户设置的温度, 则它替用户去管理制冷系统.
| 冰箱 V3.0 |
|---|
 |
kube-scheduler
Kubernates 集群的默认调度器, 主要负责在 Kubernates 集群中为一个 Pod 资源对象找到合适的节点, 并在该节点上运行. 该调度器为每个 Pod 寻找合适节点的过程称之为调度周期, 一个调度周期之内只调度一个 Pod 资源对象. 该组件监控整个集群的 Pod 资源对象和 Node 资源对象, 一旦有新的 Pod 资源对象时, 会通过调度算法为其选择最优的节点.
kubelet
该组件运行在每个 Kubernates 集群中的节点上, 用于接收, 处理, 上报 kube-apiserver 组件下发的任务.
Kubelet 进程启动时会向 Kube-apiserver 注册节点自身信息, 定时上报所在节点的资源使用状态, 用以帮助kube-schedule 调度器为 Pod 资源对象预选节点.
同时负责所在节点上的 Pod 资源对象的管理(Pod 资源对象的创建, 修改, 监控, 删除, 驱逐及Pod 声明周期管理等), 对所在节点的镜像和容器做一些清理工作, 保证节点上的镜像不会占满磁盘空间, 删除容器释放相关资源.
kubelet 开放的接口, CRI 容器运行时接口, CNI 容器网络接口, CSI 容器存储接口.
kube-proxy
节点上的网络代理, 监控 kube-apiserver 服务于端点资源变化, 同时可以通过 iptables/ipvs 等配置负载均衡器, 为一组 pod 提供统一的 tcp/udp 的流量转发和负载均衡功能.
k8s作业调度与资源管理
基本的资源限制
apiVersion: v1
kind: Pod
metadata:
name: frontend
spec:
containers:
- name: db
image: mysql
env:
- name: MYSQL_ROOT_PASSWORD
value: "password"
resources:
requests:
memory: "64Mi"
cpu: "250m"
limits:
memory: "128Mi"
cpu: "500m"
- name: wp
image: wordpress
resources:
requests:
memory: "64Mi"
cpu: "250m"
limits:
memory: "128Mi"
cpu: "500m"
CPU 的资源被称为”可压缩资源”, 资源不足时, Pod并不会退出. 内存这种资源为”不可压缩资源”, 资源不足时候就会被 OOM 杀掉.
其中资源一般还会有 limits 和 requests 值, 调度的时候, kube-scheduler 会按照 requests 的值进行计算, 但是在设置 cgroups 限制时候, 则会使用 limits 的值来进行设置.
资源分级
Guaranteed 类别
apiVersion: v1
kind: Pod
metadata:
name: qos-demo
namespace: qos-example
spec:
containers:
- name: qos-demo-ctr
image: nginx
resources:
limits:
memory: "200Mi"
cpu: "700m"
requests:
memory: "200Mi"
cpu: "700m"
pod 中的每个 container 都同时设置 requests 和 limits, 且 requests 和 limits 的值相等.
pod 被创建出来之后, 它的 qosClass 字段就会被 Kubernates 自动设置为 Guaranteed.
当仅设置 limits 没有 requests 时候, Kubernates 会自动设置与 limits 相同的 requests 值, 此时也属于 Guaranteed 情况
Burstable 类别
apiVersion: v1
kind: Pod
metadata:
name: qos-demo-2
namespace: qos-example
spec:
containers:
- name: qos-demo-2-ctr
image: nginx
resources:
limits
memory: "200Mi"
requests:
memory: "100Mi"
当 pod 不满足 Guaranteed 条件, 但至少有一个 Container 设置了 requests, 此时属于 Burstable 类别
BestEffort 类别
apiVersion: v1
kind: Pod
metadata:
name: qos-demo-3
namespace: qos-example
spec:
containers:
- name: qos-demo-3-ctr
image: nginx
如果一个 pod 既没有 requests, 也没有 limits, 则此时被归为 BestEffort
Eviction / 资源回收
当 Kubernates 所在的宿主机上不可资源短缺时, 例如memory.available 内存, nodefs.available 宿主机磁盘空间, imagefs.available 镜像存储空间等不足时候, 就会触发 Eviction.
常见的 Eviction 默认阈值如下
memory.available<100Mi
nodefs.available<10%
nodefs.inodesFree<5%
imagefs.available<15%
自定义资源回收
$ kubelet --eviction-hard=imagefs.available<10%,memory.available<500Mi,nodefs.available<5%,nodefs.inodesFree<5% \
--eviction-soft=imagefs.available<30%,nodefs.available<10% \
--eviction-soft-grace-period=imagefs.available=2m,nodefs.available=2m \
--eviction-max-pod-grace-period=600
Soft Eviction 允许为 Eviction 过程设置一段优雅杀死的时间, imagefs.available=2m 表示imagefs 不足的阈值达到 2 分钟后, 才开始进行 Eviction.
Hard Eviction 模式下, Eviction 在达到阈值后就立刻开始.
Eviction 阈值的数据主要从 cgroups 和 cAdvisor 中获得. 一旦达到阈值, 就会进入 MemoryPressure 或DiskPressure 状态(此时会打污点标记), 从而避免新的 Pod 被调度该节点上. 当 Eviction 发生时候按照如下顺序调度 Pod:
- BestEffort 类别的 Pod
- Burstable 类别, 并且资源使用量已经超过 requests 的 pod
- Guaranteed 类别资源, 仅当 pod 资源使用量超过了 limits 限制, 或宿主机本身处于 Memory Pressure 状态时候, 该类别才会被选中进行 Eviction.
- 同 Qos 类别的 Pod 也会有一定的优先级.
独享 cpu
容器中
docker run -it --rm --cpuset-cpus="1" u-stress:latest /bin/bash
Kubernates 中, 保证 Pod 为 Guaranteed 类别, 且将 CPU 资源的 requests 和 limits 设置为同一个相等的整数值
spec:
containers:
- name: nginx
image: nginx
resources:
limits:
memory: "200Mi"
cpu: "2"
requests:
memory: "200Mi"
cpu: "2"
cpuset 可把容器绑定到指定的 cpu 核上, 避免 cpushare 来共享 cpu 的计算能力. 此时可以大大减少 cpu 之间的上下文切换次数, 性能会提高很多
默认调度器
为新创建出来的 pod 寻找最合适的节点.
- 在集群所有的节点中, 根据调度算法挑选出所有可以允许该 pod 的节点 -> Predicate 调度算法
- 从 1 的结果中, 根据调度算法选择最符合条件的节点为最终结果 -> Priority 调度算法
Predicate 调度算法
该算法本质就是 filter, 按照调度策略从当前计算过滤出一系列符合条件的节点
-
GeneralPredicates 计算宿主机的 CPU 和内存资源是否够用, 简单检查下 Pod 的 requests 字段
-
Volume 过滤, 容器持久化相关调度策略
- NoDiskConflict 冲突检验, 多个 Pod 声明的 Volume 是否冲突. eg: AWS EVS 的 Volume 不允许多个 Pod 同时使用
- MaxPDVolumeCountPredicate 检验某种类型的 Volume 是否超过一定数目.
- VolumeZonePredicate 检查 Zone 高可用标签是否匹配
- VolumeBindingPredicate 检查 pod对应的 PV 的 nodeAffinity 是否跟节点匹配
-
宿主机过滤, 检验待调度的 Pod 是否满足 Node 自身的条件
- PodToleratesNodeTaints 检查 Node 的 Taint 与 Pod 的 Toleration 是否匹配, 是否可以被调度到该节点
- NodeMemoryPressurePredicate 检查当前节点的内存是否已经不够充足
-
Pod 相关过滤
-
PodAffinityPredicate 检查待调度的 Pod 与 Node 之间的亲密和反亲密关系
apiVersion: v1 kind: Pod metadata: name: with-pod-antiaffinity spec: affinity: podAntiAffinity: requiredDuringSchedulingIgnoredDuringExecution: - weight: 100 podAffinityTerm: labelSelector: matchExpressions: - key: security operator: In values: - S2 topologyKey: kubernetes.io/hostname containers: - name: with-pod-affinity image: docker.io/ocpqe/hello-pod当携带 Key 是
kubernetes.io/hostname标签的 Node中(topologyKey作用), pod 不希望任何携带 security=S2 标签 Pod 存在同一个 Node 中.
-
一般情况 k8s 调度器会启动 16 个 Goroutine 并发的为集群的所有 Node 计算 Predicates, 最后返回可以运行该 Pod 的 Node 列表
Priorities 算法
Priorities 为筛选出来的节点打分, 0-10 分制, 得分最高的节点会被 Pod 绑定
-
LeastRequestedPriority 优先选择 CPU 和 Memory 最多的宿主机, 计分规则如下
score = (cpu((capacity-sum(requested))10/capacity) + memory((capacity-sum(requested))10/capacity))/2 -
BalancedResourceAllocation 选择所有节点中各种资源分布最均衡的节点, 避免一个节点的 CPU 被大量分配, Memory 大量剩余, 计分规则如下
score = 10 - variance(cpuFraction,memoryFraction,volumeFraction)*10Fraction 就是 Pod 请求的资源 / 节点上的可用资源. variance计算两种资源 Fraction 之间的差距
-
NodeAffinityPriority 类似 PodMatchNodeSelector
-
TaintTolerationPriority 类似 PodToleratesNodeTaints
-
InterPodAffinityPriority 类似 PodAffinityPredicate
-
ImageLocalityPriority 如果待调度的镜像很大, 且已经存在于某些 Node 中, 则这些 Node 得分会相当高
由于集群和 Pod 的信息均已缓存化, 上述的算法执行过程还是很快的.
抢占式调度
一般在 Pod 调度时候时候, 直到 Pod 被更新或者集群状态发送变化, 调度器才会对该 Pod 进行重新调度. 针对高优先级的 Pod 调度失败时, 希望可以挤走某些 Node 上优先级低的 Pod, 优先保障高优先级 Pod 调度成功. 只需要定义 PriorityClass, 如下所示
apiVersion: scheduling.k8s.io/v1beta1
kind: PriorityClass
metadata:
name: high-priority
value: 1000000
globalDefault: false
description: "This priority class should be used for high priority service pods only."
Pod 中使用高优先级
apiVersion: v1
kind: Pod
metadata:
name: nginx
labels:
env: test
spec:
containers:
- name: nginx
image: nginx
imagePullPolicy: IfNotPresent
priorityClassName: high-priority
该 pod 的 spec.Priority 会被设置为 1000000, spec.nominatedNodeName设置为被强占的Node. 等待下一个调度周期时候, 决定是否需要将 Pod 运行在被强占的节点上, 主要是为了保证优雅退出时候, 集群的调度性会发生改变